InfoSecBulletin Cybersecurity for mankind
InfoSecBulletin Cybersecurity for mankind

Test before going live is important for AI developers. But there’s a problem: testing usually uses fake scenarios that often do not reflect how AI models or agents act in real life.
A new paper from OpenAI says that about 99% of the time, its models realized they were being tested. This raises an important question, the AI company mentioned. “If a model is only well behaved because it thinks it’s being tested, how do we build confidence that it’ll behave safely once it learns it’s been deployed?”
CISA alerts to cyberattacks affecting U.S. water utilities

“CyberStrike” AI-Driven Security Platform for Automated Testing

AIDCQ Propose to invest $2 billion in AI data center in Bangladesh

NVIDIA BlueField Flaw Enables Code Execution Attacks

Massive customer data from India’s Bank of Baroda surfaced online

Active Exploits Hit Fortinet, Arista: AI Discovered Linux Kernel Zero-Day

Sam Altman Claims AI “singularity” has arrived, Where Systems Improve by Themselves

Shinyhunters claimed and set deadline to publish E&Y data

Microsoft, NVIDIA and CrowdStrike Initiate Alliance for Open-Source AI Security

Google Search Results Reportedly Show Claude AI Shared Chats

The company said it found a way to solve the problem with a method called Deployment Simulation. This method helps fix the issue where the model acts nice just to impress the evaluator, instead of behaving like it would with real users.
The idea is straightforward – researchers made the models think they were already in use by giving them a mix of real prompts from users who agreed to share their data. They took away the original answer and compared what the new model said to the answer from the working model.
“Even small, subtle mismatches between evaluation and production environments can produce evaluation awareness,” the researchers wrote.
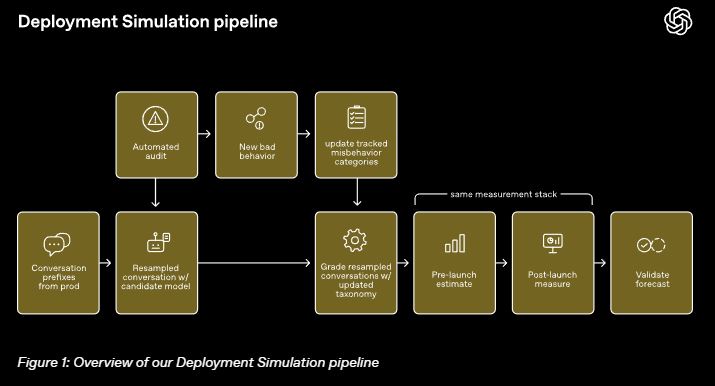
Models know they are being tested when the questions given to them are very obvious, like exam questions or requests that aren’t like real chats. The model learns these patterns and alters its behavior to match what it believes the researcher expects. The idea behind Deployment Simulation is to avoid this issue by using actual user messages since they lack those distinct patterns.
Researchers found that making a model act like it’s already in use works well. The paper says that if OpenAI developers had used Deployment Simulation before launching GPT-5.1, they would have noticed a behavior called calculator hacking. This happens when models use a browser tool as a calculator to give a number, instead of really searching the web.
To check the results, the researchers gave data to a GPT-5-Thinking model acting as a grader. The model looked at each answer and sorted it into 20 common misbehavior types that belong to two main groups – disallowed content like sexual themes, or “wrong actions” like misleading the user.
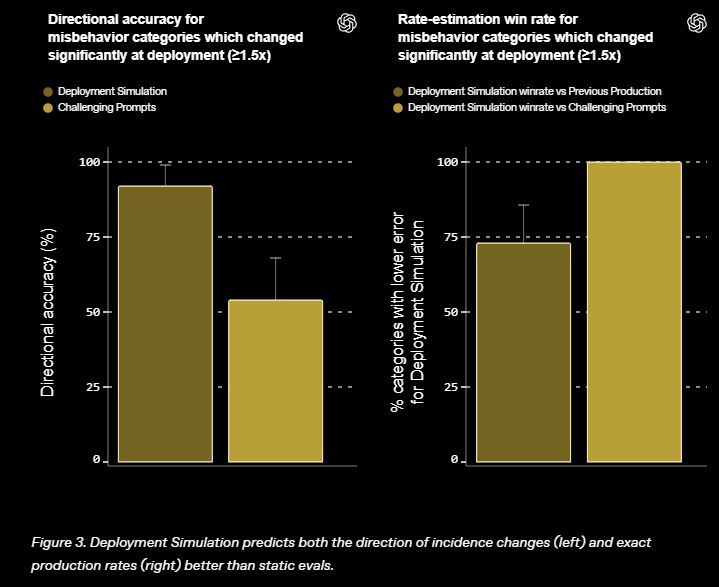
The researchers looked at how often each misbehavior showed up in the responses. They guessed how often these behaviors would happen when the model is used. OpenAI checked these guesses by using the same grading process after the model started and compared the results to their predictions. For this new method to work properly, it needs access to real, recent ChatGPT user chats. Only OpenAI has this data, which makes it hard for others to check independently.
One workaround could exist through WildChat dataset, a publicly available resource for real ChatGPT conversations that occurred between 2023 and 2024. Because the chats are dated, they provide “a loose but useful proxy for production-data-based evaluation.” One possible limitation is that the prompts may be predictive for OpenAI model behavior rather than frontier models in general, leading the authors to say they “encourage other AI labs to quantify the efficacy of public data sources as predictors of their models’ safety, thereby supporting external auditing and fairer production-like comparisons.