 InfoSecBulletin Cybersecurity for mankind
InfoSecBulletin Cybersecurity for mankind

Google has made changes to its privacy policy, allowing the use of public data to enhance its artificial intelligence products, including Bard.
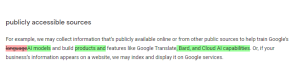
As of July 1st, the updated policy states that Google utilizes information to improve services, develop new products, and advance technologies that benefit users and the general public. Publicly available information is now employed to train Google’s AI models and create products and features such as Google Translate, Bard, and Cloud AI capabilities.
EDR-Freeze: A Tool That Puts EDRs And Antivirus Into A Coma State

First-ever AI-powered ‘MalTerminal’ Malware Uses OpenAI GPT-4 to Generate Code

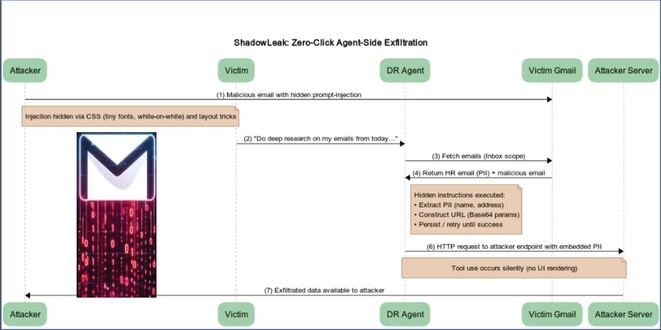
Gmail Data exposes via ChatGPT Deep Research Agent dubbed “ShadowLeak Zero-Click” Flaw
Cyber attack disrupts several European airports: check-in and boarding systems affected

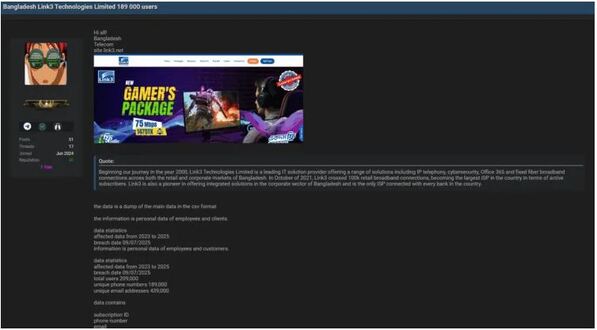
Hacker claim to breach Link3; 189,000 Users data up for sale
Check Point Hosts “Securing the Hyperconnected World in the AI Era” in Dhaka

Microsoft Confirms 900+ XSS Vulns Found in IT Services

Daily Security Update Dated : 15.09.2025

IBM QRadar SIEM Vuln Let Attackers Perform Unauthorized Actions

Major Australian Banks using Army of AI Bots to Scam Scammers

Previously, Google’s policy only mentioned the use of public data for training “language models” and specifically referenced Google Translate.
The adjustment in the policy indicates Google’s increased focus on AI endeavors without altering the user experience. It also signifies the importance of the public’s search behavior in driving further product development.
During its recent annual keynote address in California, Google showcased its latest AI innovations, including an enhanced version of Bard. Sundar Pichai, Google’s CEO, assured responsible development of these products.
However, critics have expressed concerns about companies leveraging publicly posted information for training large language models used in generative AI.
ALSO READ:
India’s health sector 2nd targeted industry by cybercriminals
OpenAI, the creator of the popular generative AI model ChatGPT, faced a proposed class action lawsuit accusing the company of data theft. The complaint, spanning nearly 160 pages, alleges that OpenAI unlawfully obtained personal data without notice, consent, or fair compensation, encompassing a vast range of internet data. The lawsuit claims that this data scraping occurred on an unprecedented scale.
Certain social media platforms have also taken measures to prevent or profit from the AI boom. Reddit, for instance, introduced charges for accessing its Application Programming Interface (API), while Twitter’s owner, Elon Musk, threatened to sue Microsoft over the use of Twitter data in AI training.
Twitter implemented limitations on the number of daily tweets users can view, attributing the move to excessive data scraping and system manipulation, though other factors may also be at play.



